Stock Index Estimation with Hidden Markov Model
Author Xinyi Wu Email xinyiwu2019@u.northwestern.edu EECS349 Machine Learning Northwestern University
This project is maintained by XinyiLeo
 Xinyi Wu
Xinyi Wu
Email: xinyiwu2019@u.northwestern.edu
Course: [EECS349] Machine Learning
College: Northwestern University
Introduction
I finally finish one of my dream this year to play with some codes in stock indexes estimation. In January to Martch I made some literature research for a wide-used hidden markov - stochastic volatility models, see Literature Research. Later in Machine learning course, I used software like Weka to give some baseline predictions and finally understood and revised some codes in HMM stock prediction. This is my first ML project in finance. Regard it as prototype, because it is far from mature to put in to reality algo trading.
Background
I myself firmly believe that algorithms is the core backbone of trading strategy, despite that human operations like legal policies and government regulation can push the stock up and down some time. The essence and charisma of machine learning algorithms will apparently stand out in high frequency trading (HFT). HFT aims to do quantitative trading by designing algorithm to buy or sell a product in a very transient time period that mostly cannot be realized by human beings. The profit of a buy/sell is very little, but we do millions of trading within a day. So the profit summed up is observable.
I used python3 to implemet codes and visualize data. I revised some codes in HMM. Those codes are for education purpose, but I revised them in my financial projects. My revised codes are here My codes.
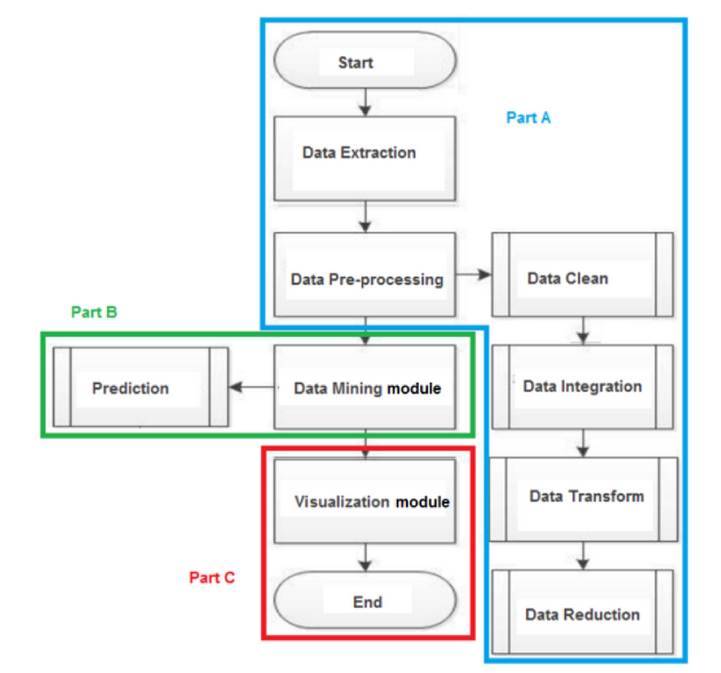
The process of my work is similiar to this flow chart. First, I analysed some significant feaures in stock estimation. For example, log return and moving averages. Second, I used some popular regression methods to make simple estimations and serve the results as baseline method. It’s noted that the baseline method performs similarly except the basic Gaussian Method. Last I followed the tutorial of GaussianHMM package to simulate the Baum-Welch training, and calculate the hidden layes of the stock indexes. I simplified the validation process. Instead of using MAP(Maximum a posteriori estimation), I simply compared the result of HMM with those baseline results from Weka.
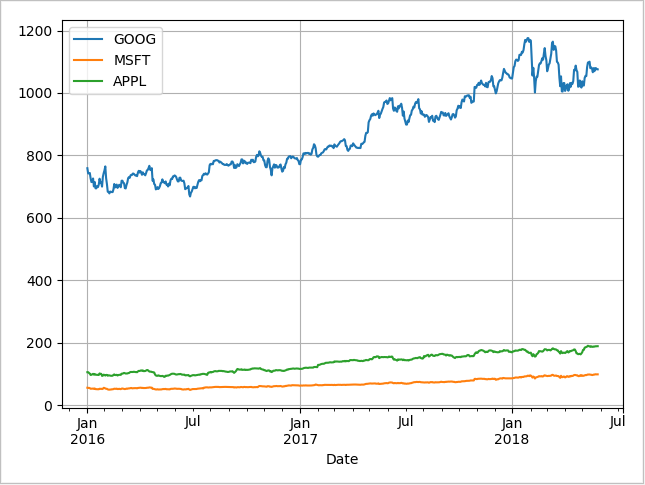
Visualization for historical data
Those are visualization of three close values: Apple Inc. (NASDAQ:AAPL), Microsoft (NASDAQ:MSFT) and Google (NASDAQ:GOOG), from 2016 January to 2018 June.
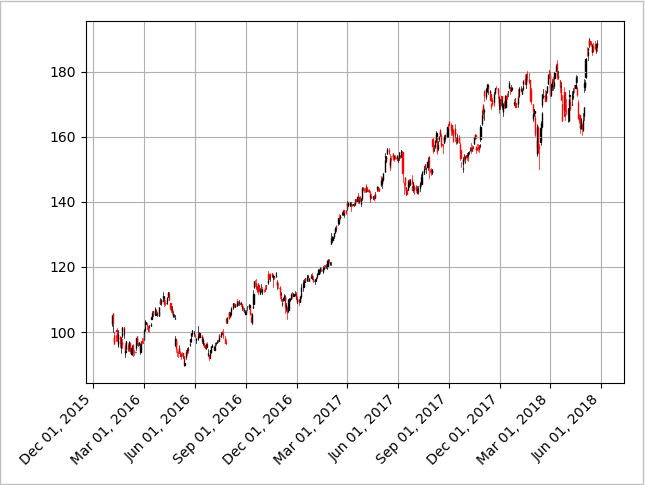
I extracted data from Morningstar Investment management company, because it has high compatibility with pandas in python. The current inputs are extracted from historical financial time series data, which includes:
- Daily Open: the price of the stock at the beginning of the trading day (it need not be the closing price of the previous trading day).
- Daily High: the highest price of the stock on that trading day.
- Daily Low: the lowest price of the stock on that trading day, and close the price of the stock at closing time.
- Adjusted close: the closing price of the stock that adjusts the price of the stock for corporate actions.
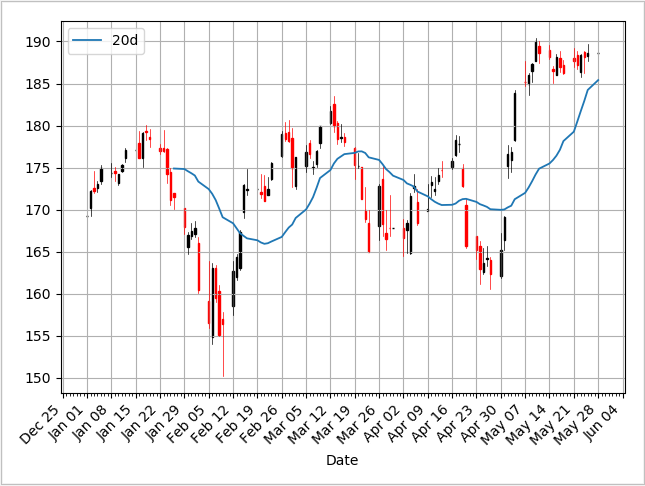
A good way to visualize all data is by Candlestick Chart. In this chart. If the daily open value is lower than the close value, the bar is black (reported a gain). If the daily close value is higher than the open value, the bar is red (reported a loss). The wicks on the top and lower part of the bar means the high value and low value of a day.
In finance, we concerned about the relative change of an asset rather than its absolute price. That’s because when we trade, we concern more about the volatility of a stock price.
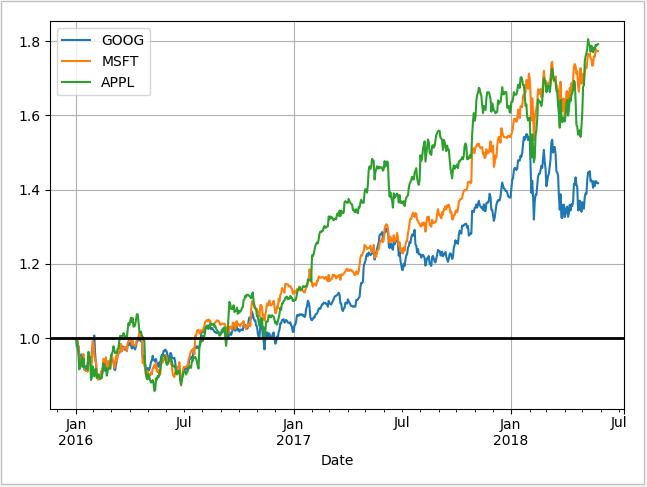
Log return is a much more useful plot. We can now see how profitable each stock was since the beginning of the period. Furthermore, we see that these stocks are highly correlated; they generally move in the same direction, a fact that was difficult to see in the other charts.
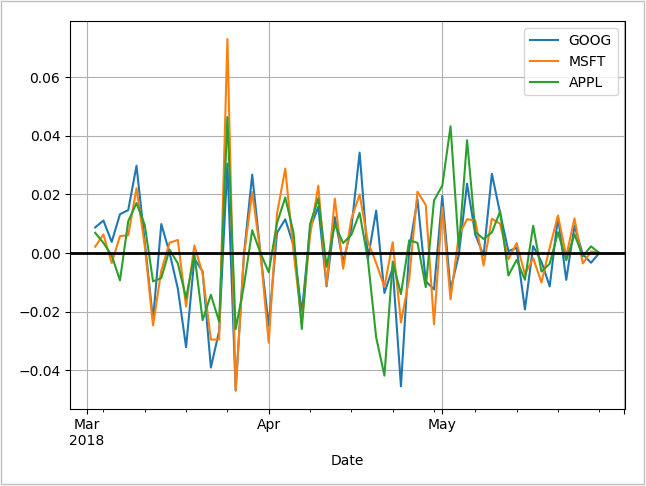
Another possible feature for stock estimation is Moving Average,
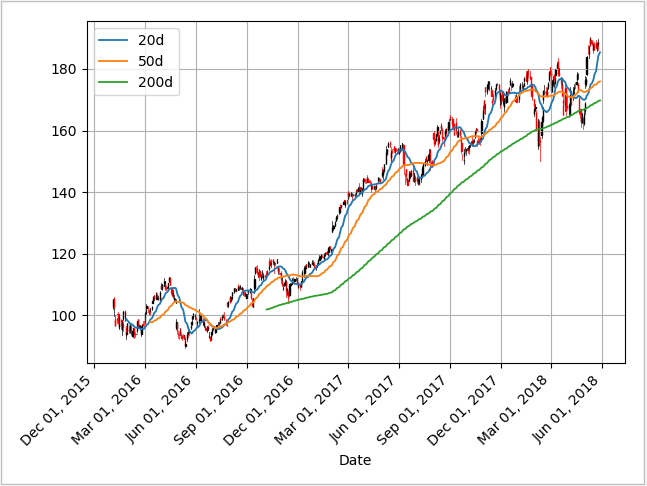
Moving averages smooth a series and helps identify trends, and help identify trends from “noise”.
Here, the 200-day moving average shows that the stock is trending downward over ina general view. Also the crossing of moving average lines indicate changes in trend, which can be used as trading signals, or indications that a financial security is changing direction and a profitable trade might be made.
Weka Baseline Estimation
First I installed package Time Series Forecasting. The Regression Techniques I used:
- Linear: conditional mean of y is a linear affine function of x.
- Multilayer Perception: Feed forward artificial neural network.
- MLP can also differentiate data which cannot be separated linearly.
- SMOreg: Support Vector Regression Method, use sequential minimal optimization algorithm.
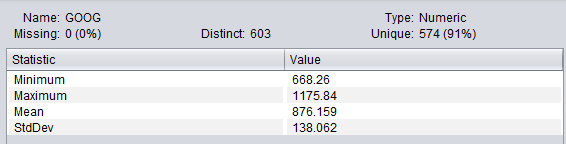
Data Collection: Used python to generate two csv files: Weka automaticlaly generate statistics (take Google (NASDAQ: GOOG) close value from 2016 Jan. 1st, to 2018 May 25th as an example):
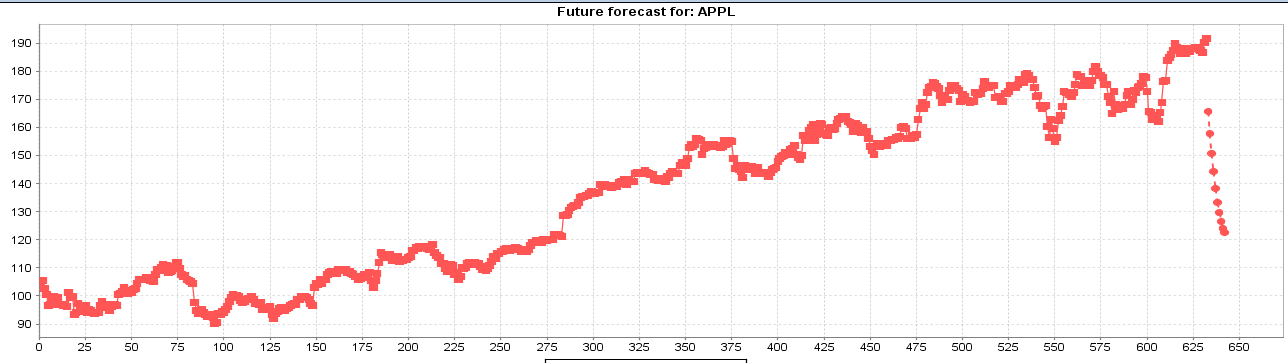
I used those methods above to forecast the result of GOOG stock index 10 days after:
-
Simple Gaussian Process Predictor (not fit)
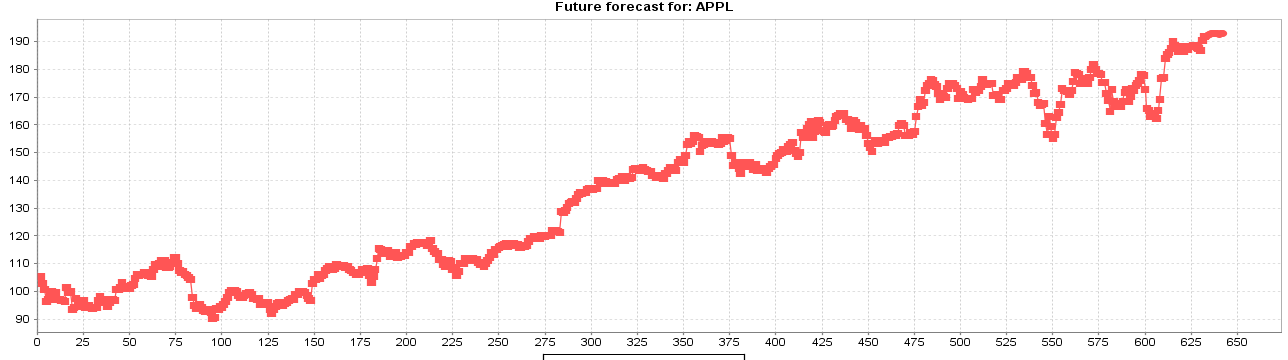
-
Linear Regression (Intuitive Method)

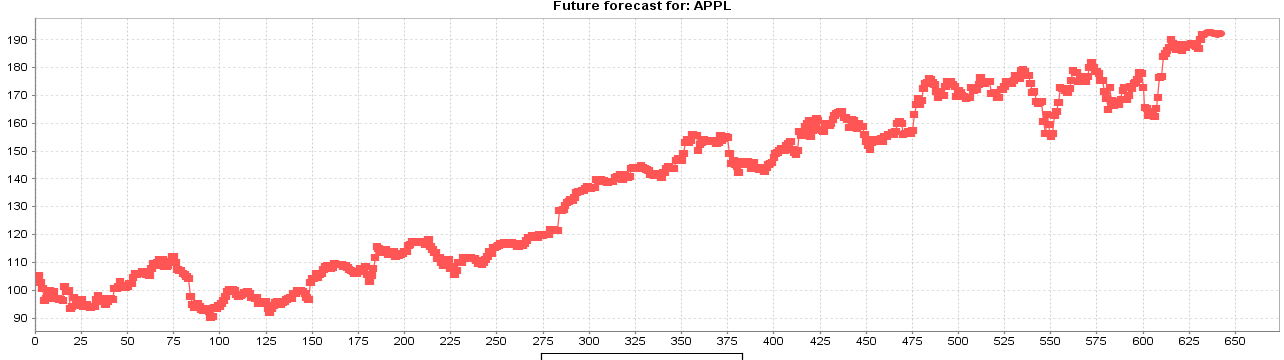
- Multilayer Perception


- SMOreg
- HoltWinters (I don’t what that is, but fancy enough to try):


Except Gaussian method, all the other perform tolerable results.
Hmmlearn Package
For those who have problem installing hmmlearn, I provide the wheel executable here HMMwheel. It does not appears on official website and it takes a while to find this.
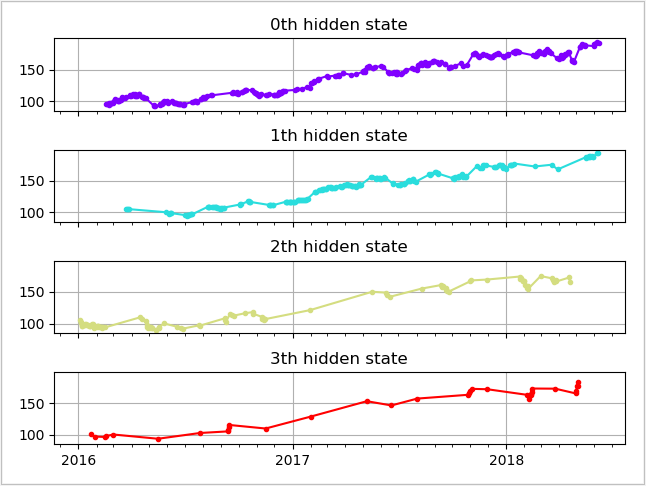
The reason of using HMM is that based on observations, we predict that the hidden states are some Gaussian Distrbutions with different parameters. We don’t know the exact number of hidden states, so I assume 4 states (simplified model).
Model Description
My code for this part is here: HMM
where A is the transition matrix, B is the matrix of observation, where
- M is number of Gaussian Mixture Components
- c_jm is the weight of m mixture component in state j
- \mu _jm is the mean vector of mth component in jth state
- N() is multi-dimensional Gaussian Distribution
In my simulation, I choose observation to be the log return of the stock. I set hidden states to 4. And I acquire data from Morningstar Company.I posted a code for training, which is partly referred by the tutorial of hmmlearn package.
import datetime import numpy as np from matplotlib import cm, pyplot as plt from matplotlib.dates import YearLocator, MonthLocator from hmmlearn.hmm import GaussianHMM from sklearn.preprocessing import scale import pandas_datareader.data as web start = datetime.datetime(2016, 1, 1) end = datetime.date.today() apple = web.DataReader("AAPL", "morningstar", start, end) dates = np.array(apple["Close"].index.levels[1]) close_v = np.array(apple["Close"].values) volume = np.array(apple["Volume"].values)[1:] # Get the variation of the price diff = np.diff(close_v) dates = dates[1:] close_v = close_v[1:] # Scale: Normalize # Input the stock return and X = np.column_stack([scale(diff), scale(volume)]) # Train Gaussian Model, Assume 4 hidden states model = GaussianHMM(n_components=4, covariance_type="full", n_iter=20) model.fit(X) # Prediction the hidden layers hidden_states = model.predict(X)The Baum-Welch Training Result is printed below:
Transition matrix: [[6.78898397e-01 2.20049840e-01 7.93357332e-02 2.17160306e-02] [2.91800841e-01 6.72692500e-01 3.35863569e-02 1.92030195e-03] [1.96634489e-01 6.95749706e-05 6.26201366e-01 1.77094571e-01] [3.59640268e-01 2.58710441e-06 2.63557237e-01 3.76799908e-01]] Means and vars of each hidden state 0th hidden state mean = [ 0.11095387 -0.13041157] var = [[ 0.62000407 -0.00778336] [-0.00778336 0.14232008]] 1th hidden state mean = [-0.06066027 -0.74767573] var = [[ 0.09386268 -0.00029546] [-0.00029546 0.23985255]] 2th hidden state mean = [-0.80832043 1.13496253] var = [[ 1.48695373 -0.57097857] [-0.57097857 1.30153418]] 3th hidden state mean = [1.64476032 1.34418623] var = [[1.96483621 0.90036972] [0.90036972 1.70227106]]And the graph:
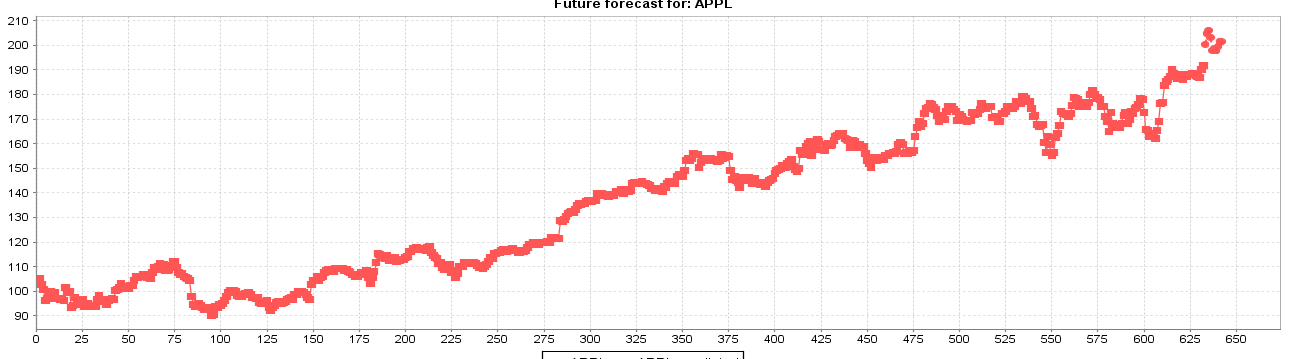
Baum-Welch is mased on Estimation-Maximum Procesure. First use EM to estimate the model, then collect expected number of trasitions from a state_i, and make statistics of expected number of transitions from S_i to S_j.
The M step is estimating the posterior of transition matrix, new observations and probability matrixes. I haven’t give real predictions for Hidden Markov Model, but based on the baseline method, the HMM looks well. I posted a graph that use similiar methods with me:
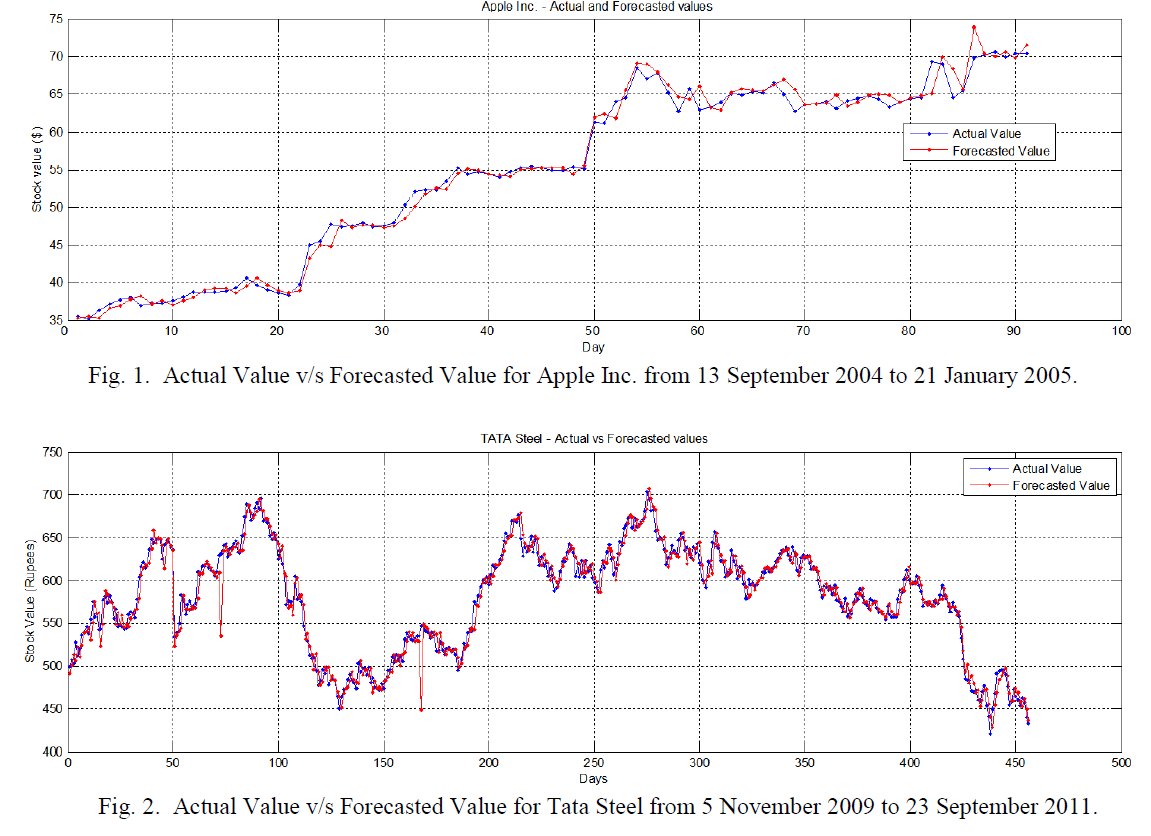
Ref: Gupta, Aditya, and Bhuwan Dhingra. “Stock market prediction using hidden markov models.” Engineering and Systems (SCES), 2012 Students Conference on. IEEE, 2012.
Improvement
Can probabily implement HMM on my own in the future(Implment Forward algorithm, backward algorithm, GetGamma, GetXi, Viterbi).
Besides HMM, other famous machine learning methods includes Artificial Neural Netowrks(ANN), Fuzzy Logic(FL), and Support Vector Machines(SVM). Can learn them in the future.